This material is presented to ensure timely dissemination of scholarly and
technical work. Copyright and all rights therein are retained by authors or
by other copyright holders. All persons copying this information are
expected to adhere to the terms and constraints invoked by each author's
copyright. In most cases, these works may not be reposted without the
explicit permission of the copyright holder.
Keith Bush,
faculty in the Department of Computer Science, University of Arkansas
at Little Rock,
Jilin Tu, PhD
candidate at the University of Illinois, Champaign/Urbana,
National Science Foundation, ECS-0245291, 5/1/03--4/30/06, $399,999,
D. Hittle, P. Young, and C. Anderson, Robust Learning Control for
Building Energy Systems.
National Science Foundation, CMS-9804747, 9/15/98--9/14/01, $746,717, with D. Hittle, Mechanical
Engineering Department, CSU,
and P. Young, Electrical Engineering Department, CSU, Robust Learning
Control for Heating, Ventilating, and Air-Conditioning Systems
National Science Foundation, CMS-9401249, 1/95--12/96, $133,196, with
D. Hittle, Mechanical Engineering,
Neural Networks for Control of Heating and Air-Conditioning
Systems
National Science Foundation, IRI-9212191, 7/92--6/94, $59,495
The Generality and Practicality of Reinforcement Learning for
Automatic Control
American Gas Association, 12/91--9/92, $49,760, with B. Willson,
Mechanical Engineering, Review of State
of Art of Intelligent Control for Large Stationary Engines
Colorado State University Faculty Research Grant, 1/920-12/92, $3,900,
Real-Time Automatic Control with Neural Networks
We presented at IJCNN, 2015 the following paper, which won the Best Paper Award.
Anderson, C., Lee, M., and Elliott, D., "Faster Reinforcement Learning After Pretraining Deep Networks to Predict State Dynamics", Proceedings of the IJCNN, 2015, Killarney, Ireland.
Abstract: Deep learning algorithms have recently appeared that pretrain
hidden layers of neural networks in unsupervised ways, leading to
state-of-the-art performance on large classification problems.
These methods can also pretrain networks used for reinforcement
learning. However, this ignores the additional information that
exists in a reinforcement learning paradigm via the ongoing sequence
of state, action, new state tuples. This paper demonstrates that
learning a predictive model of state dynamics can result in a
pretrained hidden layer structure that reduces the time needed to
solve reinforcement learning problems.
After training for 0 minutes:
After training for 10 minutes:
After training for 50 minutes:
After training for 100 minutes:
After training for 200 minutes:
Testing, with no exploration:
Testing, with no exploration, slow motion:
Another test sequence, with no exploration, slow motion:
We are investigating the use of recurrent neural networks to
approximate value functions when state cannot be completely
observed. Part of our work is based on the Echo State Network formulation.
Bush, K., Tsendjav, B.: Improving the Richness of Echo State
Features Using Next Ascent Local Search, Proceedings of the Artificial
Neural Networks In Engineering Conference (to appear), St. Louis, MO,
2005.
Bush, K., Anderson, C.: Modeling Reward Functions for Incomplete
State Representations via Echo State Networks, Proceedings of the
International Joint Conference on Neural Networks (to appear), July
2005, Montreal, Quebec.
During an extended visit to Colorado State University, Andre Barreto
developed a modified gradient-descent algorithm for training networks
of radial basis functions. His modification is a more robust approach
for learning value functions for reinforcement learning problems. The
following publication describes this work.
Jilin Tu completed his MS thesis in 2001. The following is an excerpt from his
abstract.
This thesis studies how to integrate statespace models of control
systems with reinforcement learning and analyzes why one common
reinforcement learning ar chitecture does not work for control systems
with Proportional-Integral (PI) controllers. As many control problems
are best solved with continuous state and control signals, a
continuous reinforcement learning algorithm is then developed and
applied to a simulated control problem involving the refinement of a
PI controller for the control of a simple plant. The results show that
a learning architecture based on a statespace model of the control
system outperforms the previous reinforcement l earning architecture,
and that the continuous reinforcement learning algorithm ou tperforms
discrete reinforcement learning algorithms.
In 1999, Baxter and Bartlett developed their direct-gradient class of
algorithms for learning policies directly without also learning value
functions. This intrigues me from the viewpoint of function
approximation, in that there may be many problems for which the policy
is easier to represent than is the value function. It is well known
that a value function need not exactly reflect the true value of
state-action pairs, but must only value the optimal actions for each
state higher than the rest. A function approximator that strives for
minimum error may waste valuable function approximator resources. We
devised a simple Markov chain task and a very limited neural network
that demonstrates this. When applied to this task, Q-learning tends
to oscillate between optimal and suboptimal solutions. However, using
the same restricted neural network, Baxter and Bartlett's
direct-gradient algorithm converges to the optimal policy. This work
is described in:
We have experimented with ways of approximating the value and policy functions
in reinforcement learning using radial basis functions. Gradient descent does
not work well for adjusting the basis functions unless they are close to the
correct positions and widths a priori. One way of dealing with this is to
"restart" the training of a basis function that has become useless. It is
restarted by setting its center and width to values for which the basis
function will enable the network as a whole better fit the target function.
This is described in:
C. Anderson. (1993)
Q-Learning with Hidden-Unit Restarting.
Advances in Neural Information Processing Systems, 5,
S. J. Hanson, J. D. Cowan, and C. L. Giles, eds., Morgan Kaufmann
Publishers, San Mateo, CA, pp. 81--88. (123 KB pdf)
Matt Kretchmar and I
also experimented with different basis functions, as described in
and are adapting methods for matching data probability distributions, such as
Kohonen's self-organizing maps approach, to the temporal-difference paradigm
of reinforcement learning.
My interest in efficient ways of learning good representations for
reinforcement learning systems started during my graduate school days with my
advisor, Andy Barto, at the
University of Massachusetts:
M. Kokar, C. Anderson, T. Dean, K. Valavanis, and W. Zadrony.
Knowledge representation for learning control.
In Proceedings of the 5th
IEEE International Symposium on Intelligent Control,
Philadelphia, PA, Sept. 1990, pp. 389--399.
C. Anderson. Tower of hanoi with connectionist networks:
learning new features. Proceedings of the Sixth
International Workshop on Machine Learning, Cornell University,
June, 1989.
C. Anderson. Learning to control an inverted pendulum with neural
networks.
IEEE Control Systems Magazine, 9, 3, April, 1989.
C. Anderson. Feature generation and selection by a layered network of
reinforcement learning elements: Some initial experiments.
M.S. Dissertation, Computer and Information Science Department,
Technical Report 82-12, University of Massachusetts, Amherst, MA, 1982.
A. Barto and C. Anderson. Structural learning in connectionist systems,
Proceedings of the Seventh Annual Conference of the Cognitive Science
Society, Irvine, CA, 1985.
A. Barto, R. Sutton, and C. Anderson. Neuron-like adaptive elements
that can solve difficult learning control problems, IEEE
Transactions on Systems, Man, and Cybernetics, SMC-13,
5, pp. 834--846, 1983.
A. Barto, C. Anderson, and R. Sutton. Synthesis of nonlinear control
surfaces by a layered associative network, Biological Cybernetics,
43, pp. 175-185, 1982.
One domain in which we are developing applications of reinforcement learning
is the heating and cooling of buildings. In some initial work we have
investigated reinforcement learning, and some other neural-net ways of
learning to control, on an accurate simulation of a heating coil:
Robust control theory can be used to prove the stability of a control
system for which unknown, noisy, or nonlinear parts are "covered" with
particular uncertainties. We have shown that a reinforcement learning
agent can be added to such a system if its nonlinear and time-varying
parts are covered by additional uncertainties. The resulting theory
and techniques guarantee stability of a system undergoing
reinforcement learning control, even while learning!
Kretchmar, R.M., Young, P.M., Anderson, C.W., Hittle, D.,
Anderson, M., Delnero, C., and Tu, J. (2001) Robust Reinforcement
Learning Control with Static and Dynamic Stability.
International Journal of Robust and Nonlinear Control, , vol. 11,
pp. 1469--1500.
Kretchmar, R.M., Young, P.M., Anderson, C.W., Hittle, D.C., Anderson,
M.L., and Delnero, C.C. (2000)
Robust
Reinforcement Learning Control with Static and Dynamic Stability.
Technical Report CS-00-102, Department of Computer Science, Colorado
State University, Fort Collins, CO 80523. (1 MB pdf)
"Mixture of experts" networks have been shown to automatically decompose
difficult mappings into a combination of simple mappings. We extended these
techniques for reinforcement learning and tested them with the pole-balancing
problem, as reported in
In complex, delayed-reward problems, a considerable amount of experience is
required to propagate reward information back through the sequence of states
that might affect that reward. We are exploring one way to speed up this
propagation of information by adapting the multigrid approach from solving
large distributed systems of PDE's to the reinforcement learning paradigm. Robert Heckendorn and I
have tested this using a multigrid version of value iteration:
and Stew Crawford-Hines and
I have worked with a multigrid form of Q learning:
C. Anderson and S. Crawford-Hines.
Multigrid Q-Learning.
Technical Report CS-94-121. Colorado
State University, Fort Collins, CO 80523, 1994. (202 KB compressed postscript)
Another domain in which we have applied reinforcement learning is the control
of traffic lights. This work applies SARSA to a simulation of traffic flow
through intersections:
T. Thorpe, Vehicle Traffic Light Control
Using SARSA, Masters Thesis, Department of Computer Science, Colorado
State University, 1997. (172 KB compressed postscript)
With Darrell Whitley, we
have compared reinforcement learning algorithms with genetic algorithms for
learning to solve the inverted pendulum problem. In our experiments, we found
that the genetic algorithm resulted in more robust solutions:
D. Whitley, S. Dominic, R. Das, and C. Anderson
Genetic Reinforcement Learning for Neurocontrol Problems.
Machine Learning, 13, pp. 259--284, 1993.
In other control work unrelated to reinforcement learning, we have shown
that expensive sensors for air-fuel ratio can be replaced by inexpensive
cylinder pressure sensors by using neural networks to learn a mapping from the
pressure trace to the actual air-fuel ratio. This work is in collaboration
with Bryan Willson.
Several applications for which reinforcement learning is suggested to
be a good solution are described here:
Anderson, C. W., and Miller, W.T. (1990) A set of challenging control
problems. In Neural Networks for Control,
ed. by W.T. Miller, R.S. Sutton, and P.J. Werbos, MIT Press, pp. 475--510.


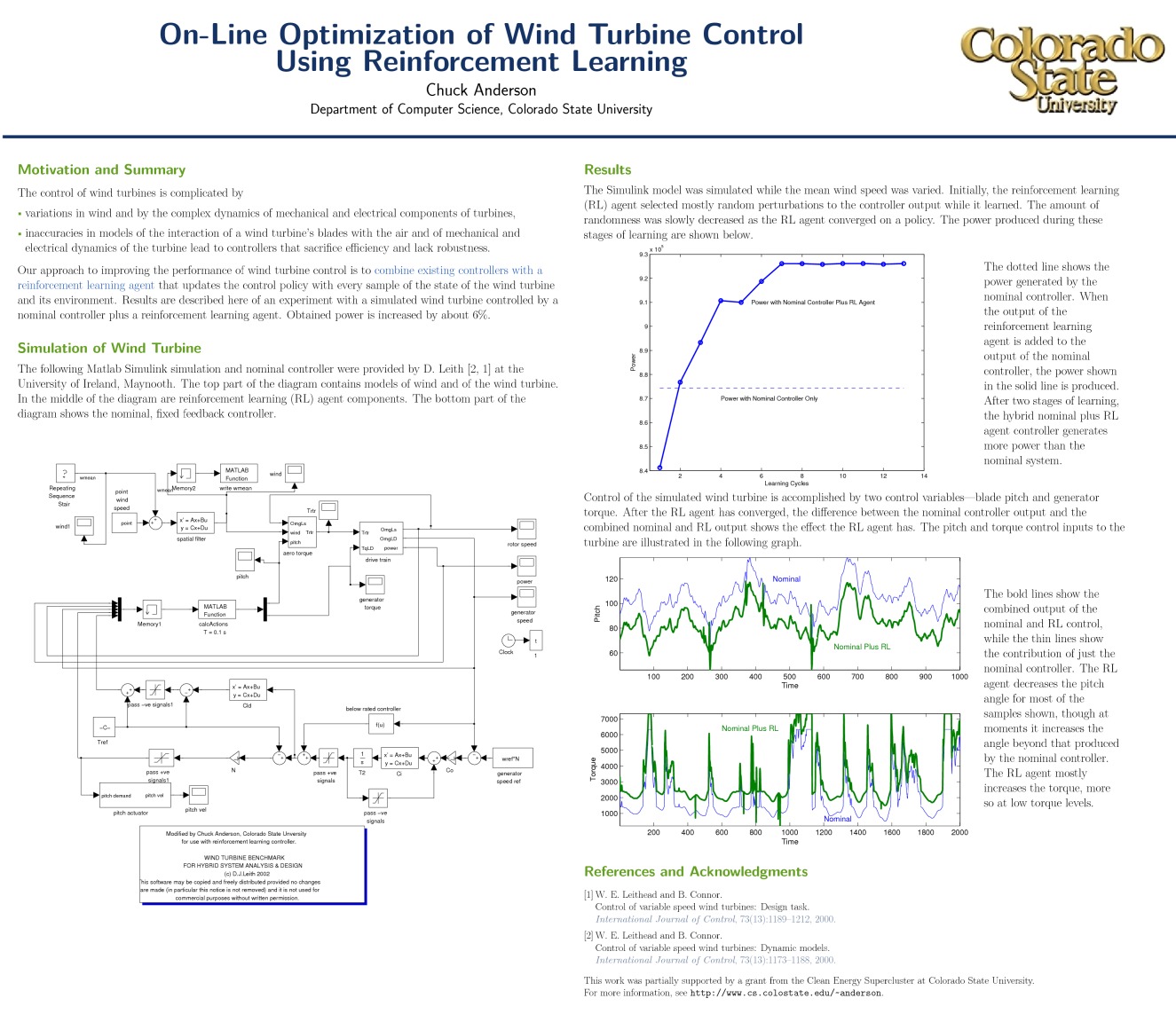 On August 13th, we presented a poster titled On-Line Optimization of Wind Turbine
Control using Reinforcement Learning at the 2nd Annual CREW Symposium
at Colorado School of Mines. CREW stands for the Center for Research and Education in Wind.
On August 13th, we presented a poster titled On-Line Optimization of Wind Turbine
Control using Reinforcement Learning at the 2nd Annual CREW Symposium
at Colorado School of Mines. CREW stands for the Center for Research and Education in Wind.