
Professor
Department of Computer Science
CwC Project

Communication Through Gestures, Expression and Shared Perception
Principal Investigators
- Bruce Draper, Colorado State University (PI).
- J. Ross Beveridge, Colorado State University.
- Jaime Ruiz, University of Florida.
Context
As the capabilities of computers and machines improve, the underlying dynamic of human-computer interaction changes from a series of commands to a process of communication. In previous models, users solved problems on their own, figuring out what they need the machine to do, and how the machine should do it. They then tell the machine to carry out their commands. On this approach, the focus of HCI is on making this instruction as easy as possible. As machines become more intelligent and gain access to new resources and effectors, however, the dynamic changes. In the new model, users still have an initial goal, but the problem-solving process is now partially automated. The user and the machine work together to find the best way to solve the task, and depending on the specific abilities of the machine and the user, the two may work cooperatively to implement the solution. Thus the dynamic of human-computer interaction changes from giving and receiving orders to a peer-to-peer conversation.
Goals
This is a dynamic (and partial) list, and all work so far is in the domain of blocks world...- Elicit the common gestures people use naturally when communicating with each other about physical tasks.
- Learn to recognize these common gestures in real time, as performed by naive users.
- Understand how to combine gestures with words, so as to convey more information more naturally than through language along
- Understand how gestures interact with dialog
- Exploit the topics above in the context of two way human-machine communication.
Current Progress
Our avatar currently has two modes: expert mode, in which she assumes the user knows how to use the system, and teaching mode, in which she models what the user does and doesn't know in terms of gestures and words. In teaching mode, when a user may not know a gesture or term, the avatar uses it, hoping that the user will learn to use the system better through the natural instinct to mimic a partner is a conversation. Below are two videos that show the system in both the expert and teaching modes.
The difference between the two modes can be subtle, we so compiled a quick video of some of the differences.
Eliciting Natural Gestures
One of our goals is to elicit and then learn to recognize the gestures that people use naturally. The idea is to build interfaces that naive users can use, without having to adapt to the machine. At the very least, multi-modal interfacces should be easy to learn.
To elicit natural gestures, we had pairs of naive subjects instruct each other in how to build block structures over audio/visual links, as shown in the picture below. The result is a fascinating data set. We have four hours of (pain-stakingly hand-labeled) video of subjects building block structures when they can both see and hear each other. We have four more hours of (labeled) video with the microphone turned off, so that the signaler and builder can see but not hear each other. Finally, we have four hours of video where the signaler's camera is turned off, so that the instructions are only audio.
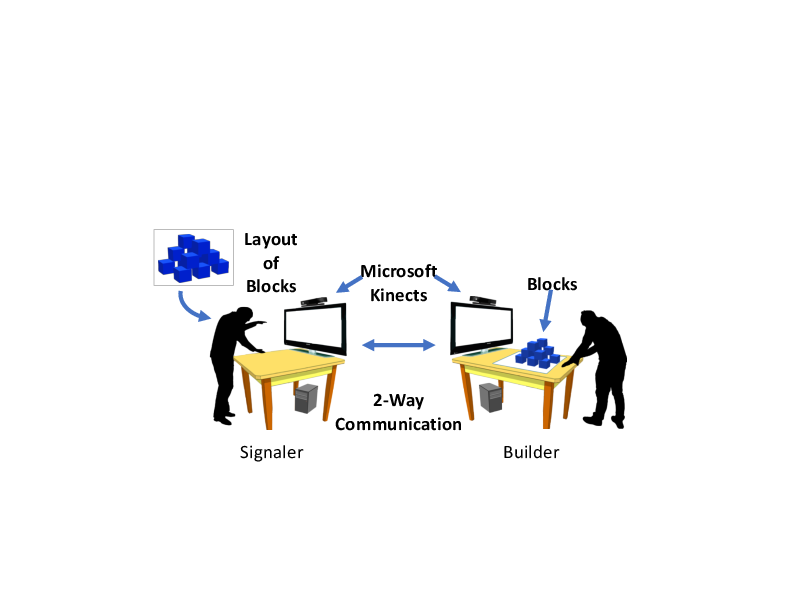
If you are interested in the data, it is publicly available (some restrictions apply). The data can be downloaded from here. You can learn more about the data set from the following paper:
- Isaac Wang, Mohtadi Ben Fraj, Pradyumna Narayana, Dhruva Patil,
Gururaj Mulay, Rahul Bangar, R. Ross Beveridge, Bruce A. Draoer and
Jaime Ruiz. EGGNOG: A continuous, multi-modal data set of
naturally occurring gestures with ground truth labels, IEEE
Conf. on Automatic Face and Gesture Recognition, Washington DC,
Examples of Real-time Gesture-based Communication
This first example shows a person (Guru) trying to get an avatar (Diana) to build a staircase out of seven blocks. This is the same video as on Bruce Draper's homepage, but a different view of it. This time we are showing episim, the epistomologic knowledge viewer from Brandeis. It shows not only the on-going trial, but a representation of what Diana knows about Guru. Pink squares represent words, gestures, or properties that -- as far as Diana knows -- Guru doesn't know yet. When Guru has uses a word, gesture or property, the square turns a dull gray, suggesting that he probably knows that term. When it turns dark blue, he definitely knows it. (Brandeis picked the color scheme, not me.)
Finally, this is the "under the hood" video (from a slightly older version of the system). It shows the internal workings of the real-time gesture recognition system while the user performs the same task as in the first video above. (Don't try to synch them up in terms of time -- we can't record both views at once, so we made the user -- a different user -- do it again :) But the sequence of gestures is similar. The left side shows the probabilty of each of the 35 right hand poses in real time. The middle column shows the probabilities for the 35 left hand gestures. The right columns shows the probabilities for right arm, left arm and head gestures.