Performance on a series of tasks or a composite task often depends on the order in which the tasks or subtasks are addressed. An example of an order effect is shown in Figure 3.5. The Phoenix planner uses three general plans to fight simulated forest fires, called model, shell and mbia. It begins work with one, but if the plan seems not to be working, it adopts another. (Sometimes it will select the same plan again, and update its parameters .) Thus, the first plan has three outcomes: successful containment of the fire (denoted S in Figure 3.5), outright failure to contain the fire (F), or replanning (R). Sometimes a third attempt is made, but we will concentrate on the first two, here. It is striking that model does very well when it is the first plan (84 success, 15 failures, and 15 replans) and shell and mbia do quite poorly, whereas the pattern is reversed for the second plan: model does poorly when it is the second plan whereas shell and mbia do rather better. Figure 3.5 shows a clear order effect: the success of a plan depends on when the plan is tried.
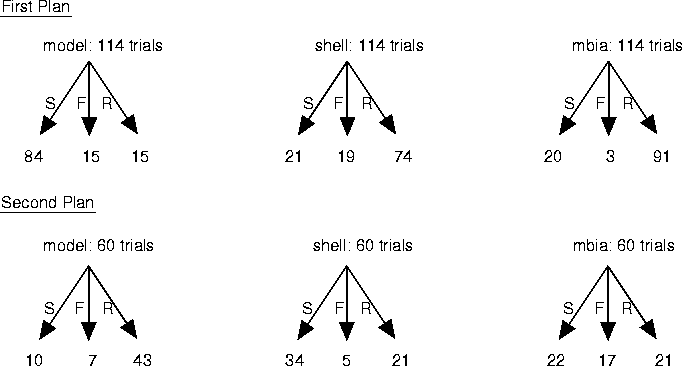
Figure 3.5 The success of a plan depands on when it is tried.
Order effects can confound experiment results when different orders are systematically (and inadvertently) associated with treatment and control conditions. A set of exam problems might be completed more quickly in one order than another, because one problem might prepare you for another but not vice versa. So if a control group of students is presented test problems in a ``good'' order and the treatment group gets the problems in a ``bad'' order, then a positive effect of treatment might be washed out by the effect of order; or, if the treatment group gets the ``good'' order, the effect of treatment (which could be zero) might appear larger than it really is.
Although the solution seems to be to present problems to the treatment and control groups in the same order, this does not control for the possibility that one group is more sensitive to order than the other. The treatment group, for instance, might have received training that makes them relatively insensitive to the order of presentation of standardized test problems. Then, if both groups get problems in a ``bad'' order, the treatment group will outperform the control group. You might think this is at it should be: the treatment group received training, and the effect of the training is demonstrated on the exam. But what should we conclude if both groups get problems in a ``good'' order and they perform equally? Should we conclude that the treatment is ineffectual? Clearly, if we select just one order to present problems to the treatment and control groups, we risk selecting an order that will not show the superiority of the treatment group.
If we knew which orders were ``good'' and which were ``bad,'' then we could probably construct a ``bad'' order that highlights the treatment group. Unfortunately, we generally cannot anticipate order effects. This is because they arise from interactions among problems or tasks, and it is notoriously difficult to consider all such interactions. Virtually anything can create an order effect. For example, a program might have to garbage-collect twice if it performs tasks in a particular order, and just once if it adopts a different order.
Still, the idea of presenting problems in a single order to both treatment and control groups is appealing, so let us see whether it can be rescued. If the number of test problems is small, we could probably find a ``bad'' order that highlights the superiority of the treatment group. Then we could run the experiment and find a difference between it and the control group. Unfortunately, we don't know how much of the difference is due to the insensitivity of the treatment group to order, and how much is due to other skills imparted by the treatment. The only way to find out is to run both groups again, this time with problems presented in a ``good'' order.
We have discussed three problems:
A single technique called counterbalancing avoids all three problems. The basic idea is to present problems in all possible orders to both the treatment and control groups. This avoids systematically associating ``bad'' orders with the control group and ``good'' orders with the treatment group (and vice versa). This renders irrelevant one reason for trying to anticipate order effects--to avoid systematically inflicting them on the treatment or control group. In fact, far from having to anticipate order effects, counterbalancing helps us discover them, thus problem 2 is moot. To see how counterbalancing helps us simultaneously discover order effects and solve problem 3, consider a simple case in which we present two problems a and b to programs P1 and P2 in all possible orders, and we measure the time to solve both. Here are the results:
| P1 | P2 | |
| Order a, b | 10 | 15 |
| Order b, a | 12 | 20 |
Program P1 solves problems a and b more quickly than program P2, irrespective of the order of presentation, which, we discover, makes a difference. So P1 is better than P2. Part of this advantage is due to P1's ability to handle problems in any order, part is due to other factors. We can estimate the relative contributions of these parts (and solve problem 3) as follows: when problems are presented in the best possible order, P2's time is 150% of P1's, and in the other order, P2's time is 167% of P1's. The 67% advantage enjoyed by P1 in the second case is thus a sum: 17% due to P1's ability to handle problems in any order plus 50% due to other factors.
Unfortunately, counterbalancing is expensive. We generally cannot afford to present problems to both treatment and control groups in all possible orders. A set of just five problems yields 5! = 120 orders. And it is frustrating to run a beautifully (and expensively) counterbalanced experiment only to find no order effects. For example, the fully-counterbalanced, hypothetical experiment described earlier might have yielded these results:
| P1 | P2 | |
| Order a, b | 10 | 15 |
| Order b, a | 10 | 15 |
In this case counterbalancing tells us only that it is unnecessary! To minimize the expense of counterbalancing, researchers often approximate the technique by selecting just a few orders from among the many possible. For example, if our programs had to solve five problems, we might run an experiment with, say, ten randomly-selected orders instead of the 120 possible:
| P1 | P2 | |
| abcde | 10 | 15 |
| cbade | 11 | 17 |
| aecbd | 10 | 14 |
| dceab | 13 | 20 |
| bcaed | 9 | 11 |
| deabc | 14 | 22 |
| cadeb | 10 | 15 |
| dcbae | 12 | 21 |
| abdec | 11 | 14 |
| baedc | 9 | 15 |
If the results are all pretty similar, we might conclude that order effects are small or nonexistent. However, it appears in this example that whenever d is the first problem in the order, P2 gets a suspiciously high score. (In chapter 7, we describe a technique for automatically flagging suspicious associations between orders and scores.)
While counterbalancing controls for order effects in the tasks that we, the experimenters, present to programs, these programs are designed to take most task-ordering decisions automatically, beyond our control. In fact, programs such as planners exploit order effects by design. Counterbalancing is neither desirable nor even possible. It's one thing to counterbalance the order in which the Phoenix planner fights two fires, and quite another to counterbalance the order in which it selects plans, and virtually impossible to control the order in which it selects bulldozers to assign to the plans. To counterbalance tasks at all levels of planning, we would have to completely rewrite Phoenix's task scheduler, after which Phoenix would no longer be a planner! Counterbalancing should eliminate spurious effects. But if the difference between two versions of a planner is that one exploits constraints among tasks better than the other, then the effects of task order are not spurious, they are precisely what we hope to find in an experiment. Clearly, we must reserve counterbalancing for those situations in which order effects are spurious and potentially large enough to swamp or significantly inflate treatment effects. Even then, probably won't be able to afford full counterbalancing, and will have to settle for a few orders, selected randomly.