In factorial experiments, every combination of levels of factors is sampled. For instance, an experiment to find effects of gender and age in high school might have six conditions: two levels of gender crossed with three grade levels. Some general tactics yield well-designed factorial experiments.
If an independent variable x is categorical, then the number of levels of x is generally determined by the number of ``natural'' categories (e.g., male and female), or by merging similar categories if the number of categories is very large (e.g., all occupations are merged into blue-collar, white-collar, etc.). If x is an interval variable, then your design should generally have more than two levels of x. This way, you have the opportunity to find a rough functional relationship between x and the dependent variable y. It is more difficult to see functional relationships if x is ordinal, functional models but it might still be worth having more than two levels of x, if only to check that y doesn't spike or drop unexpectedly for particular values of x.
It is often helpful to measure more than one dependent variable, so you can see how different aspects of a system behave in different conditions. For example, two common measures of performance for message understanding systems are recall and precision. Let's say perfect performance involves providing exactly one correct answer to each of ten questions about a message. Recall is the number of correct answers divided by ten, precision is the number of correct answers divided by the total number of answers. A system can get a high recall score by answering each question many ways, but its precision score will suffer. Alternatively, a system that doesn't answer a question unless it is sure the answer is correct might have a low recall score but high precision. By plotting both measures of performance, as shown in Figure 3.13, you can see whether you have a ``try everything'' or a ``conservative'' system.
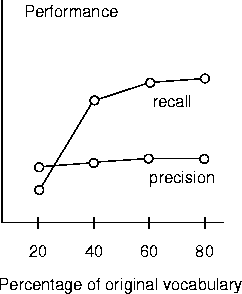
Figure 3.13 It is often useful to have more than one dependent variable.
Factorial experiments often involve two or three independent
variables, but rarely more. The great advantage of factorial designs
is that they disclose interactions between independent
variables--they show how the relationship between y and ![]() is influenced by
is influenced by ![]() . Imagine we have two ways to
parse messages: the first relies heavily on syntax and the
second doesn't parse in the conventional sense but infers the message
structure from semantics. We want to know which approach is most
sensitive to vocabulary size. This is a classical two-factor design,
with hypothetical results illustrated in Figure 3.14.
The first panel shows the semantic parser is always a bit
better than the syntactic parser, and this advantage is roughly
constant at all levels of vocabulary size. Vocabulary size doesn't
affect the parsers differently; these factors don't interact. The
second pane shows what are perhaps more realistic results: successive
levels of vocabulary size have diminishing influence on the
performance of the syntactic parser and increasing influence on the
performance of the semantic parser; in this case, the factors do
interact.
. Imagine we have two ways to
parse messages: the first relies heavily on syntax and the
second doesn't parse in the conventional sense but infers the message
structure from semantics. We want to know which approach is most
sensitive to vocabulary size. This is a classical two-factor design,
with hypothetical results illustrated in Figure 3.14.
The first panel shows the semantic parser is always a bit
better than the syntactic parser, and this advantage is roughly
constant at all levels of vocabulary size. Vocabulary size doesn't
affect the parsers differently; these factors don't interact. The
second pane shows what are perhaps more realistic results: successive
levels of vocabulary size have diminishing influence on the
performance of the syntactic parser and increasing influence on the
performance of the semantic parser; in this case, the factors do
interact.
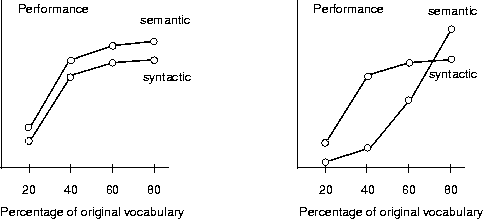
Figure 3.14 Factorial designs disclose that the influence of one variable on another sometimes depends on a third variable.
In general, you can increase the sensitivity of an experiment by having your system solve the same set of problems in each condition. This way, you can be sure that differences in performance across conditions are due to the factors that define the conditions, and are not influenced by the problems that happen to be selected in each condition. If you select different sets of problems in each condition, there is always the possibility that, by chance, the problems in one condition will be easier than those in another. Recall, too, that the variance in a dependent variable can obscure differences between conditions, so we want to remove as many sources of variance--other than the independent variable--as possible.
It will simplify statistical analysis if each condition contains the same number of data. For example, each of the points in Figure 3.14 might represent the mean performance on ten messages. The same messages might be tested in each condition, or each point might represent ten unique messages, but either way, it is best to have the points represent equal numbers of data.
The default hypothesis in statistical hypothesis testing is that no influence or effect exists; you reject this hypothesis only if you have strong evidence. Because the role of evidence is to demonstrate an influence, it is difficult to demonstrate no influence. For example, the precision score in Figure 3.13 increases only a little as vocabulary size increases, and a statistical test might judge the increase to be insignificant. Should we therefore conclude that vocabulary size does not affect precision? Technically, we should not; statistical machinery was set up to find influences, not non-influences. In practice, experiments are designed to demonstrate non-influences (see section 7.3.1) but you should remember that it is much easier to fail to demonstrate an influence than it is to demonstrate one.