Mycin, developed at Stanford University by E.H.Shortliffe (Buchanan and Shortliffe, 1984) in the mid 1970s, was the first expert system to demonstrate impressive levels of performance in a medical domain. Mycin's task was to recommend therapy for blood and meningitis infections. Because the cause of an infection was often unknown, Mycin would first diagnose the cause and then prescribe therapy. Typically, Mycin would ask a bunch of questions about a particular case and then suggest one or more therapies to cover all the likely causes of the infection. Sometimes, cases involved more than one infection.
Before we review how Mycin was actually evaluated, let's consider how we might do it. Stanford University is home to some of the world's experts on blood and meningitis infections, so perhaps we should show them a reasonable number of problems that Mycin had solved and ask them what they think. Good idea, bad execution. Perhaps half the experts would say, ``I think Mycin is great!'' and the other half would say, ``I think Mycin is the thin end of a very dangerous wedge; computer diagnosticians, over my dead body!'' A more likely scenario--we have seen it often--is the experts would be very enthusiastic and give glowing reviews, much the way that parents gush over their children. What we need is not opinions or impressions, but relatively objective measures of performance.
We might ask the experts to assess whether Mycin offered the correct therapy recommendation in each of, say, 10 cases. The experts would be told how to grade Mycin when it offered one of several possible recommendations, and how to assign points to adequate but suboptimal therapy recommendations. This approach is more objective but still flawed. Why? It doesn't control for the prejudices of the experts. Enthusiastic experts might give Mycin ``partial credit'' on problems that anti-Mycin experts would say it failed.
A standard mechanism for controlling for judges' biases is
blinding. In a single-blind study, single-blind study
the judges don't know whether they are judging a computer program or a
human. Mycin was evaluated with a single-blind study.
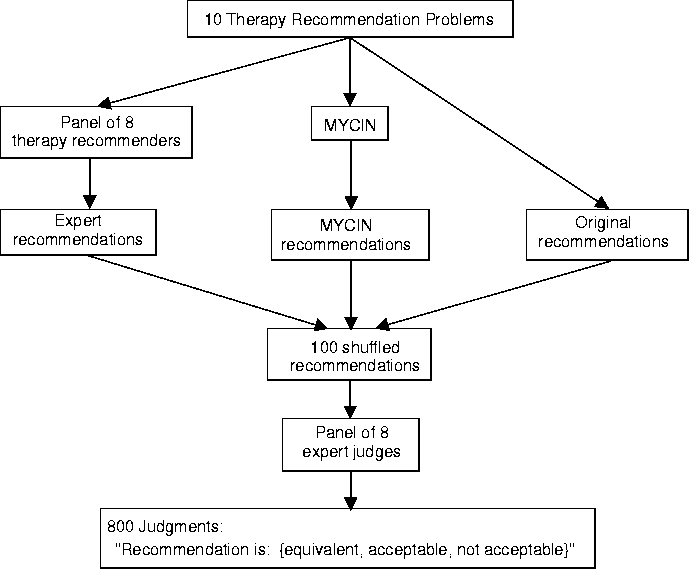
Shortliffe asked each of eight humans to solve ten therapy recommendation
problems. These were real, representative problems from a case library at
Stanford Medical School. Shortliffe collected ten recommendations from
each of the eight humans, ten from Mycin, and the ten
recommendations made originally by the attending physicians in each case,
for a total of 100 recommendations. These were then shuffled and given to
a panel of eight expert judges. Each judge was asked to score each
recommendation as a) equivalent to their own best judgment, b) not
equivalent but acceptable, or c) unacceptable. This design, which controls
for judges' bias by blinding them to the origin of the recommendations, is
shown in Figure 3.3
.
Figure 3.3
You might think this design is an ironclad evaluation of Mycin's performance. It isn't. The design as stated fails to control for two possible explanations of Mycin's performance.
Imagine an expert system for portfolio management, the business of buying and selling stocks, bonds and other securities for investment. I built a system for a related problem as part of my Ph.D. research. Naturally I wondered who the experts were. One place to look is a ranking, published annually, of pension-fund managers-- the folks who invest our money for our old age. I learned something surprising: very few pension-fund managers remain in the top 10% of the ranking from one year to the next. The handful that do could be considered expert; the rest are lucky one year, unlucky the next. Picking stocks is notoriously difficult (see Rudd and Clasing, 1982), which is why I avoided the problem in my dissertation research. But suppose I had built a stock picking system. How could I have evaluated it? An impractical approach is to invest a lot of money and measure the profit five years later. A better alternative might be to convene a panel of experts, as Shortliffe did for Mycin, and ask whether my stock-picking program picked the same stocks as the panel. As with the Mycin judges, we face the problem that the experts won't agree. But the disagreements signify different things: Mhen portfolio managers don't agree, it is because they don't know what they are doing. They aren't experts. Few outperform a random stock-picking strategy. Now you see the crucial control condition: One must first establish that the ``experts'' truly are expert, which requires comparing ``experts'' to nonexperts. Nonexpert performance is the essential control condition.
Surely, though, Professors of Medicine at Stanford University must be real experts. Obviously, nothing could be learned from the proposed condition; the Professors would perform splendidly and the novices would not. Shortliffe didn't doubt the Professors were real experts, but he still included novices on the Mycin evaluation panel. Why?
Imagine you have built a state-of-the-art parser for English sentences and you decide to evaluate it by comparing its parse trees with those of expert linguists. If your parser produces the same parse trees as the experts, then it will be judged expert. You construct a set of test sentences, just as Shortliffe assembled a set of test cases, and present them to the experts. Here are the test sentences:
Because your program produces parse trees identical to the experts', you assert your program performs as well as experts. Then someone suggests the obvious control condition: Ask a ten-year-old child to parse the sentences. Not surprisingly, the child parses these trivial sentences just as well as the experts (and your parser).
Shortliffe put together a panel of eight human therapy recommenders and
compared Mycin's performance to theirs. Five of
the panel were faculty at Stanford Medical School, one was a senior
resident, one a senior postdoctoral fellow, and one a senior medical
student. This panel and Mycin each solved ten problems, then
Shortliffe shipped the solutions, without attribution, to eight judges around
the country. For each solution that a judge said was equivalent or
acceptable to the judge's own, Shortliffe awarded one point. Thus, each
human therapy recommender, and Mycin, could score a maximum of
80 points--for eight ``equivalent or acceptable" judgments on each of the
ten problems. The results are shown in Figure 3.4. Figure 3.4
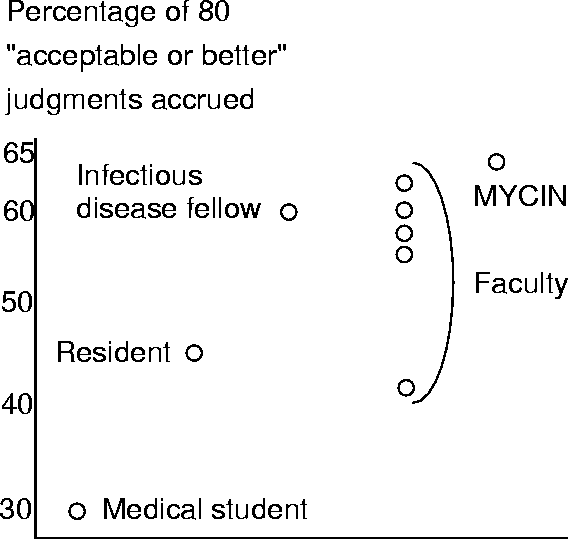
The expert judges actually agreed slightly more with Mycin's recommendations than with those of the Stanford Medical School faculty.
By including novices on the Mycin evaluation panel, Shortliffe achieved three aims. Two relate to control--ruling out particular explanations of Mycin's high level of performance. One explanation is that neither Mycin nor the experts are any good. Shortliffe controlled against this explanation by showing that neither Mycin nor the experts often agreed with the novice panel members. This doesn't prove that Mycin and the Professors are better than the novices, but they are different. (If five Professors recommend, say, ampicillin as therapy, and five novices give five different answers, none of which is ampicillin, then ampicillin isn't necessarily a better therapy, but which answer would you bet your life on?) Another explanation of Mycin's performance is that Shortliffe gave Mycin easy cases to solve. If ``easy'' means ``anyone can do it,'' then the novices should have made the same therapy recommendations as the experts, and they didn't.
The third advantage of including novices on the evaluation panel is that it allowed Shortliffe to test a causal hypothesis about problem-solving performance in general, and Mycin's performance in particular. Before discussing the hypothesis, consider again the results in Figure 3.4. What is the x axis of the graph? It is unlabeled because the factors that determine performance have not been explicitly identified. What could these factors be? Mycin certainly does mental arithmetic more accurately and more quickly than Stanford faculty; perhaps this is why it performed so well. Mycin remembers everything it is told; perhaps this explains its performance. Mycin reasons correctly with conditional probabilities, and many doctors do not (Eddy 1982); perhaps this is why it did so well. Even if you know nothing about Mycin or medicine, you can tell from Figure 3.4 that some of these explanations are wrong. The mental arithmetic skills of Stanford faculty are probably no better than those of postdoctoral fellows, residents, or even medical students; nor are the faculty any more capable of reasoning about conditional probabilities than the other human therapy recommenders; yet the faculty outperformed the others. To explain these results, we are looking for something that faculty have in abundance, something that distinguishes fellows from residents from medical students. If we didn't already know the answer, we would certainly see it in Figure 3.4: knowledge is power! This is the hypothesis that the Mycin evaluation tests, and that Figure 3.4 so dramatically confirms:
Knowledge-Is-Power Hypothesis: Problem soving performance is a function of knowledge; the more you know, the better you perform.
To be completely accurate, Figure 3.4 supports this hypothesis only if we define high performance as a high degree of agreement with the eight expert judges, but if Shortliffe didn't believe this, he wouldn't have used these judges as a gold standard.
Let's review the tactics discussed in this section: