In an ideal experiment, one controls all variables except the one that is manipulated, but in reality one can directly control very few variables. In Figure 3.1, for instance, we list four variables besides gender that might account for math scores, and we could easily have expanded the list to include dozens more. To control for the possibility that parent's occupation affects math scores, we would have to compare Abigail, whose parents are doctors, with another child of doctors, not with Fred, whose parents are artists. In the extreme, we would have to compare Abigail with a 67'' tall boy who has three siblings, doctors for parents, and is viewed by his teacher as ``an angel.'' And if we could find such an individual, he probably wouldn't have been born in the same town as Abigail, or delivered by the same physician, or fed the same baby food, or dropped on his head on the same dark night that Abigail was. Agreed, this example seems a bit ridiculous, but you can't prove that these factors don't account for Abigail's math scores. So if you take the definition of ``extraneous variable'' literally (i.e., extraneous variables are other possible causes) then the identity of the physician who delivered Abigail is an extraneous variable, and must be controlled in an experiment.
In practice, extraneous variables are not merely ``possible causes''; they are ``plausible causes.'' It is plausible to believe that a teacher's view of a student influences her math scores; it is unlikely that the identity of the physician who delivered the baby who became the student influences her math scores. Thus, we distinguish extraneous variables from noise variables.
Experiments control extraneous variables directly, but noise variables are controlled indirectly by random sampling. Suppose we are concerned that a student's math scores are affected by how many siblings, s, he or she has. We can control s directly or let random sampling do the job for us. In the first instance, treating s as an extraneous variable, we would compare math scores of girls with s = 0 (no siblings) to scores of boys with s = 0, and girls with s = 1 to boys with s = 1, and so on. Alternatively, we can treat s as a noise variable and simply compare girls' scores with boys' scores. Our sample of girls will contain some with s = 0, some with s = 1, and so on. If we obtained the samples of girls and boys by random sampling, and if s is independent of gender, then the distribution of s is apt to be the same in both samples, and the effect of s on math scores should be the same in each sample. We cannot measure this effect--it might not even exist--but we can believe it is equal in both samples. Thus random sampling controls for the effect of s, and for other noise variables, including those we haven't even thought of.
The danger is that sampling might not be random. In particular, a noise variable might be correlated with the independent variable, in which case, the effects of the two variables are confounded. Suppose gender is the independent variable and s, the number of siblings, is the noise variable. Despite protestations to the contrary, parents want to have at least one boy, so they keep having babies until they get one (this phenomenon is universal, see Beal, 1994). If a family has a girl, they are more likely to have another child than if they have a boy. Consequently, the number of children in a family is not independent of their genders. In a sample of 1000 girls, the number with no siblings is apt to be smaller than in an equally-sized sample of boys. Therefore, the frequency distribution of s is not the same for girls and boys, and the effect of s on math scores is not the same in a sample of girls as it is in a sample of boys. frequency distribution Two influences--gender and s--are systematically associated in these samples, and cannot be teased apart to measure their independent effects on math scores. This is a direct consequence of relying on random sampling to control for a noise variable that turns out to be related to an independent variable; had we treated s as an extraneous variable, this confounding would not have occurred. The lesson is that random sampling controls for noise variables that are not associated with independent variables, but if we have any doubt about this condition, we should promote the noise variables to extraneous variables and control them directly. You will see another example of a sampling bias in section 3.3.
We hope, of course, that noise variables have negligible effects on dependent variables, so confounding of the kind we just described doesn't arise. But even when confounding is avoided, the effects of noise variables tend to obscure the effects of independent variables. Why is Abigail's math score 720 when Carole, her best friend, scored 740? If gender was the only factor that affected math scores, then Abigail's and Carole's scores would be equal. They differ because Abigail and Carole are different: one studies harder, the other has wealthier parents; one has two older brothers, the other has none; one was dropped on her head as a child, the other wasn't. The net result of all these differences is that Abigail has a lower math score than Carole, but a higher score than Jill, and so on.
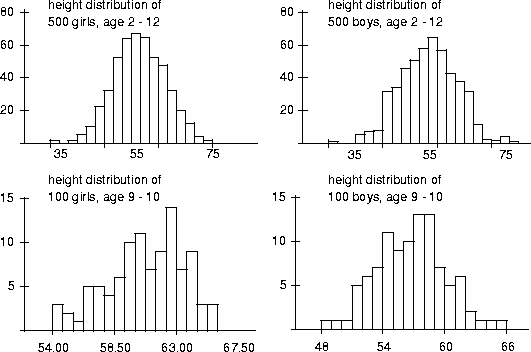
Figure 3.2 Distribution of heights for boys and girls at direrent ages.
The variance in math scores within the sample of girls is assumed to result from all these noise variables. It follows, therefore, that you can reduce the variance in a sample by partitioning it into two or more samples on the basis of one of these variables--by promoting a noise variable to be an extraneous or independent variable. For example, Figure 3.2 shows the distributions of the heights of boys and girls. In the top two distributions, the age of the children is treated as a noise variable, so, not surprisingly, the distributions have large variances. In fact, the variances are such that height differences between boys and girls are obscured. By promoting age to be an extraneous or independent variable--by controlling for age directly instead of letting random sampling control for its effect--we can reduce variance and see effects due to gender. The bottom two distributions represent boys and girls in the more tightly constrained 9-10 year age bracket. They have smaller variances (compare their horizontal axes to those of the top two graphs) and we can now see that girls are taller than boys.
In sum, experiments test whether factors influence behavior. Both are represented by variables. In manipulation experiments, one sets levels of one or more independent variables, resulting in two or more conditions, and observes the results in the dependent variable. Extraneous variables represent factors that are plausible causes; we control for them directly by reproducing them across conditions. Noise variables represent factors we assume have negligible effects. They are controlled by random sampling, if the sampling is truly random. If noise factors turn out to have large effects, then variance within conditions will be larger than we like, and it can be reduced by treating noise variables as extraneous or independent (i.e., directly controlled) variables.