Dependency Detection applies contingency table analysis to build a set of simple models of causes of a particular event's occurrence. It was designed to be the first step in a partially automated debugging process, which was originally developed for the Phoenix planning system [5]. Consequently, the algorithm and the examples refer to failure recovery actions of the Phoenix planner and the failures that occurred during the planner's execution. It has been used as well for detecting sources of search inefficiency in another planning system.
Dependency detection searches Phoenix execution traces for
statistically significant patterns: co-occurrences of particular
precursors (events or combinations of events) leading to a target
event (i.e., a failure) . The execution traces are
sequences of events: alternating failures and the recovery actions
that repaired them, e.g.,
. The execution traces are
sequences of events: alternating failures and the recovery actions
that repaired them, e.g.,
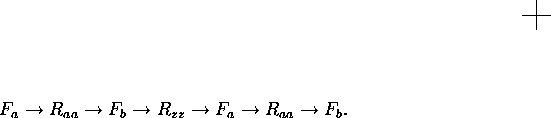
The idea is that the appearance of repetitive sequences
(which will be called patterns to distinguish potential models
from the data), such as  , may designate
early warnings of severe failures or indicate partial causes of the
failures.
, may designate
early warnings of severe failures or indicate partial causes of the
failures.
Dependency detection exhaustively tested the significance of a well-defined set of patterns using contingency table analysis. The set of patterns is crucial because the patterns form the hypothesized models of causality for the data; a model that is not in the set will not be tested. The pattern set defines the size of the search space. To test each pattern, the algorithm needs a method of matching the pattern to the data and, to reduce redundancy and potentially conflicting models, needs a method of reconciling similar models. Dependency detection exploits characteristics of the Phoenix data; the set of patterns included all combinations of a precursor followed immediately by a failure; the precursor could be a single failure, a single recovery action or a two event sequence of a failure and a recovery action. (The precursor-failure patterns are written as [F F], [R F] and [FR F], respectively.) While [R F] and [FR F] match the event streams exactly, the [F F] pattern matches by ignoring the value of the intervening recovery action. Similar patterns are reconciled by exploiting a property of the underlying statistic.
The dependency detection algorithm has three steps.
to the table.
Figure 1.1
shows an example contingency table for the sequence [  ]
(which indicates that the precursor is a recovery action of type aa
and the failure is of type b). The four
counts are: the number of times the precursor is followed by the
target failure (upper left cell) and not followed by the target
failure (upper right cell), as well as when other precursors are
followed by the failure (lower left cell) and not followed by it
(lower right cell). A G-test of the example table produces G = 6.79,
p ;SPMlt; .009, suggesting a dependency
between the two events.
]
(which indicates that the precursor is a recovery action of type aa
and the failure is of type b). The four
counts are: the number of times the precursor is followed by the
target failure (upper left cell) and not followed by the target
failure (upper right cell), as well as when other precursors are
followed by the failure (lower left cell) and not followed by it
(lower right cell). A G-test of the example table produces G = 6.79,
p ;SPMlt; .009, suggesting a dependency
between the two events.

Table 1.1: Sample contingency table from Dependency Detection for
sequence [ ]
For each significant pattern (  ), the third step prunes
out similar (overlapping) patterns using a Homogeneity G-test. Two
patterns overlap when one pattern contains either a particular failure
or a particular recovery action as precursor (i.e., are either [R F]
or [F F]) and the other contains both (i.e., [FR F] where one of the
events in the precursor is the same as in the singleton). The process
exploits the additivity property of the G-test by treating the data
for the [FR F] pattern as a partition of the [F F] or [R F] (whichever
is being compared) data and results in a list of all significant
patterns found in the execution traces. (Details of the pruning
process can be found in [6].)
), the third step prunes
out similar (overlapping) patterns using a Homogeneity G-test. Two
patterns overlap when one pattern contains either a particular failure
or a particular recovery action as precursor (i.e., are either [R F]
or [F F]) and the other contains both (i.e., [FR F] where one of the
events in the precursor is the same as in the singleton). The process
exploits the additivity property of the G-test by treating the data
for the [FR F] pattern as a partition of the [F F] or [R F] (whichever
is being compared) data and results in a list of all significant
patterns found in the execution traces. (Details of the pruning
process can be found in [6].)
Computationally, dependency detection requires a complete sweep of the
execution traces to test each pattern. The number of patterns equals
the number of types of failures squared (for FF) plus the number of
failures squared times the number of recovery actions (for FRF) plus
the number of recovery actions times the number of failures (for
RF). In total, this is roughly  where M is the length of
the event traces, N is the number of types of events in the traces
(i.e., the total number of types of recovery actions and
failures). N is cubed to subsume the FR F case in which the
precursor has both a failure and a recovery action; if we wished to
consider longer patterns of events, then the 3 would be replaced by
the length of the desired pattern.
where M is the length of
the event traces, N is the number of types of events in the traces
(i.e., the total number of types of recovery actions and
failures). N is cubed to subsume the FR F case in which the
precursor has both a failure and a recovery action; if we wished to
consider longer patterns of events, then the 3 would be replaced by
the length of the desired pattern.