Problems whose solutions optimize an objective function defined over multiple steps generally require considerable a prior knowledge. Dynamic programming techniques are able to solve such multi-stage, sequential decision problems, but they require complete knowledge of the state space, including state transition probabilities. Bertsekas (1995) has recently published a two-volume text that covers current dynamic programming theory and practice. These techniques start with the value of an objective function for the final states. This value is backed up to all states from which each final state can be reached in one step. Using the known transition probabilities, these preceding states are assigned values. This process continues until all states are assigned values. Once this value function is learned, the optimal action can be selected for any state by choosing the action that maximizes the expected value of the next state. The learned value function is a prediction of the sum of future values. Values defined by the problem's objective function are often called reinforcements, because the learning algorithms were first developed as models of classical and instrumental conditioning in animals.
In most real problems, state transition probabilities are not known. Reinforcement learning methods (Bertsekas and Tsitsiklis, 1995) are a way to deal with this lack of knowledge by using each sequence of state, action, and resulting state and reinforcement as a sample of the unknown underlying probability distribution. This information is used to incrementally learn the correct value function. Typically this requires a large number of such samples. The need for long learning periods is offset by the ability to find solutions to problems that could not be solved using conventional dynamic programming methods.
Recent theoretical developments in the reinforcement learning field have made strong connections between dynamic programming and reinforcement learning. Some reinforcement learning algorithms have been proved to converge to the dynamic programming solution. However, these proofs rely on particular forms of the adaptive value function; these forms are such that there is little transfer of learning from one situation to others, so they do not scale well to large problems. To handle larger problems, continuous value functions are required that do transfer from one learning experience to another.
One structure commonly used to learn value functions are neural networks. This is the approach I have taken, starting in 1986 when I trained neural networks to estimate the value function for an inverted pendulum problem (Anderson 1986, 1989). I have also applied reinforcement learning to other problems, including real control problems such as control of heating in buildings (Anderson, et al., 1997) and difficult search problems such as the Towers of Hanoi puzzle (Anderson, 1987). A number of other control problems that are good candidates for reinforcement learning are defined in Anderson and Miller (1990).
The mountain car problem is another problem that has been used by several researchers to test new reinforcement learning algorithms. This involves a two-dimensional world consisting of a valley and a mass that must be pushed back and forth to gain enough momentum to escape the valley. The following section describes my implementation of this problem and a general MATLAB environment for simulating reinforcement learning control problems and solutions.
A MATLAB Environment and GUI for Reinforcement Learning
Most methods for approximating the value function in reinforcement learning are intuitively represented as matrices. A good example is the use of neural networks to learn the value function. The implementation of such value functions and learning algorithms are very concise and intuitive in MATLAB. The interpreted environment of MATLAB also greatly reduces the time it takes to modify the algorithm and test the effects of the changes. In addition to the benefits of the high-level MATLAB language and the interpreted environment, I have found MATLAB's visualization capabilities extremely helpful in debugging the algorithms, gaining insight into the effects of changes to the algorithms, and teaching others the capabilities of reinforcement learning.
Combining all of the visualization methods with the ability to modify parameters and control the running of the simulation via a graphical user interface (GUI) results in the researcher being "closer" to the algorithm. A more intuitive grasp of the effects of various parameter values is gained by removing the programming effort it would take to change parameters without the GUI. The GUI editor guide has been very useful in quickly putting together a very functional user interface.
The figure below shows the GUI I have built for demonstrating reinforcement learning algorithms. The code is publicly available in this gzipped tar file. You are welcome to download and use this code; please acknowledge this source if you find it useful. It is not guaranteed to be free of bugs. The value function is being learned by a neural network consisting of radial basis functions (Kretchmar and Anderson, 1997). In the upper left is a graph of the two-dimensional world in which the mountain car lives. The car is represented by a box whose color indicates which direction, left or right, the reinforcement learning agent is currently pushing. This display can be activated and deactivated by clicking on the update button below the graph. Deactivating it allows the simulation to run faster. The number of trials between graph updates can be modified by changing the value in the text box next to the update button. Similar update buttons and text boxes appear for every other graph. The upper right graph shows the performance of the reinforcement learning agent while it is learning. Performance is measured by the number of steps from initial random positions and velocities of the car to the step at which the car leaves the valley. Performance is plotted versus the number of trials. In the middle region of the figure are current parameter values in editable text fields. Changes made by the user to any of these values are immediately effective. The lower left graph shows the current estimate of the value function. The reinforcement learning agent is learning a prediction of the number of steps required to leave the valley from every state, where a state consists of a position and velocity of the car. The user can change the view of this three-dimensional surface by clicking and moving the mouse on this graph. The lower right graph shows the actions the learning agent would take for each state of the car using the current estimate of the value function. Pictured is a late stage of learning after a good value function has been learned. The green area covers states for which the car is pushed right, and in the red area the car is pushed left. A plot of the trajectory of the car's state for the current trial will be added to this axis.
In the menubar, one pull-down menu has been added, called Run. When pulled down, the user sees the choices Start, Reset, and Pause. Start obviously will start the simulation. Once started, the Pause menu item becomes enabled, allowing the user to pause the simulation at any time. The Reset menu item will re-initialize the reinforcement learning agent so it can again learn from scratch.
The implementation is based on three main structures for the task, the learning agent, and the simulation. Each structure includes fields for parameters, such as the mass of the car in the task structure, and display update flags and tag names. This simulation environment and GUI are still under development. The implementation will be moved to the object-based representation to facilitate the construction of new learning agents and tasks. This will be tested by implementing a second control task and at least one search task, such as a simple game like Tic-Tac-Toe or a puzzle like the Towers of Hanoi.
The resulting environment for experimenting with reinforcement learning methods will be very helpful, both to students wanting to learn more about reinforcement learning and to researchers wanting to study novel extensions of current reinforcement learning algorithms or to apply reinforcement learning to new tasks. A primary goal in designing this environment is flexibility to try different tasks and different value function representations (Kretchmar and Anderson, 1997). The popularity of reinforcement learning is growing rapidly. Stories in the popular press are covering reinforcement learning accomplishments, such as the achievements of Tesauro's program that learns to play backgammon at a master's level, and textbooks are starting to appear. An easy-to-use environment for learning about and experimenting with reinforcement learning would be very popular and a good companion to new textbooks.
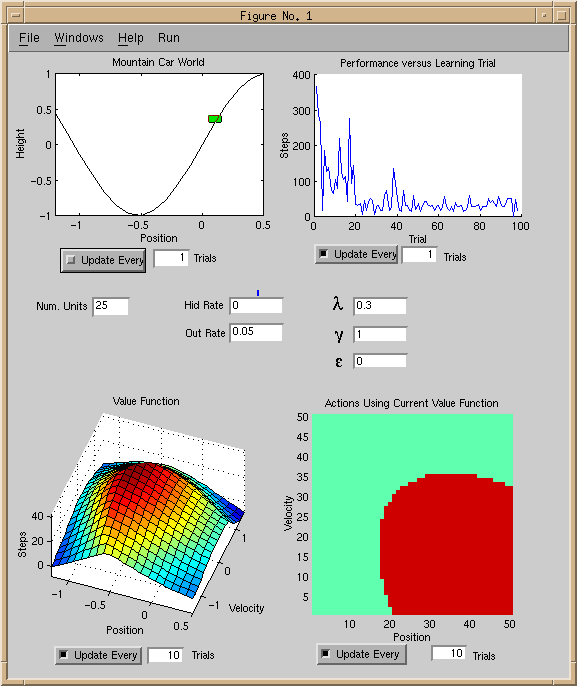 GUI for observing and manipulating the learning and performance of reinforcement learning algorithms while solving the mountain car problem.
GUI for observing and manipulating the learning and performance of reinforcement learning algorithms while solving the mountain car problem.